
Data Fetching
Data fetching is a very important part of server-side rendering applications. Through the content of this chapter, readers can understand some deep-level knowledge of server-side rendering applications.
Static Method Data Fetching
The ssr framework proposes defining fetch.ts files for data fetching, which is essentially the same as asyncData proposed by Vue and getInitialProps proposed by Next.js - they all belong to static methods.
About what static method is: methods that can be obtained without instantiating the class. For example, the following code:
class Foo {}
Foo.bar = () => {}
此时的 bar 函数即为 static method, 我们可以直接通过 Foo.bar() 来调用它,而不需要 new Foo()。这里大部分用户可能会有疑惑,为什么要使用一个静态方法来进行数据的获取,而不是像传统 SPA 应用一样直接写在组件的生命周期当中呢。
Students who have some understanding of server-side rendering will know that in the server, only lifecycles like created/componentWillMount will be executed, while lifecycles like mounted/componentDidMount won’t be executed. So is it feasible to write data fetching logic in created? The answer is also no.
Since our data fetching logic is generally asynchronous, during the server-side rendering process, components won’t re-render when props/state changes like in client-side applications. For example, the following code cannot get correct rendering results:
class Foo extends React.component {
construtor (props) {
super(props)
this.state = {
value: 'foo'
}
}
async componentWillMount() {
const newValue = await Promise.resolve('bar')
this.setState({
value: newValue
})
}
render() {
return (
<div>{this.state.value}</div>
)
}
}
In the above code, we expect the rendering result to be value=bar, but the actual result is not like this. Interested students can actually run the above code to observe the specific phenomenon. Similarly, in Vue, we also cannot get correct data. So we need to define a static method to fetch data.
fetch.ts Specification
We abstract the fetch.ts file specification on the basis of static methods as the entry file for data fetching. Because for some large teams, we can usually use rpc type calls on the server side, or directly call Node Service code to get data without going through http requests. So in fetch.ts, we might write server-side related code, hence we separate it into a file for maintenance.
The definition of fetch.ts is that it’s the entry file for page-level components to fetch data, not including child components. Since on the server side, before a component is truly rendered, we don’t know which child components it depends on. So we can’t call child components’ fetch. Of course, there are other ways to solve this problem. See the supplementary content at the end of this article. In Vue scenarios, this problem is easy to solve, and we will add support for child component data fetching in Vue scenarios in future versions.
fetch.ts files are divided into two types:
Layout fetch
Layout level fetch (optional), defined at web/components/layout/fetch.ts path.
Meaning: Layout level fetch is used to initialize some common data that all pages will use. If this file exists, it will be called. The returned data will be merged with page-level fetch and returned to developers. Layout scenarios only allow one fetch file to exist.
Page-level fetch
Page-level fetch (optional, can exist multiple), defined at web/pages/xxx/fetch.ts path.
Meaning: Page-level fetch will be called when currently accessing the path corresponding to the frontend page component.
fetch and render Correspondence
The correspondence between fetch files and render is as follows:
- When there’s only one
fetchfile, allrenderfiles in the current folder correspond to thisfetchfile - When multiple
fetchfiles exist,renderfiles correspond one-to-one withfetchfilenames, for examplerender.vue=>fetch.ts,render$id.vue=>fetch$id.ts
fetch Call Timing
Here we divide it into two cases: Server-Side Rendering Mode and Client-Side Rendering Mode.
Server-Side Rendering Mode
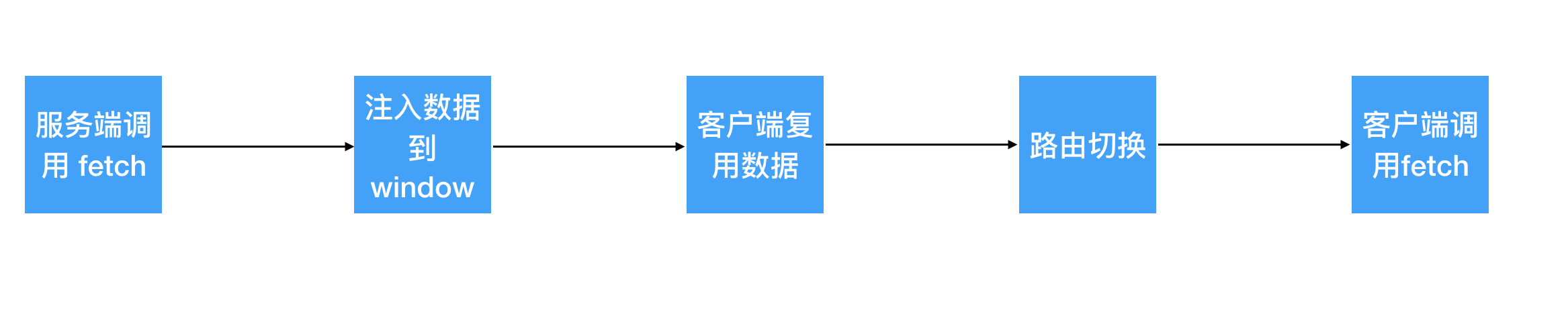
Will be called during the server-side rendering execution process. During the client activation process, it will reuse the data obtained by the server and injected into window for initialization. It won’t fetch again on the client side. When the client performs frontend route switching, it will call the fetch corresponding to the page it’s going to. The fetch in the figure below represents layout fetch + page fetch. If they exist, they will be called.
Client-Side Rendering Mode
At this time, the server won’t perform any data fetching operations, only rendering an empty html skeleton. The actual data fetching and DOM rendering operations will all be executed on the client side. This is consistent with the behavior of traditional client-side SPA applications that everyone is familiar with.

Judging Current Environment
In the default examples, we use the __isBrowser__ variable to mark the current environment to let developers understand that this file might be executed in two different environments: server-side and client-side. This variable is automatically injected during the build process without developers needing to pay attention. In real applications, except for companies or departments with mature infrastructure that call interfaces in other languages through RPC at the Node.js layer, most companies still use HTTP form to request services. In this case, there’s no need to judge the environment through __isBrowser__. You can directly use axios to initiate HTTP requests. axios will automatically judge the current environment - if it’s client-side, it uses xhr objects to initiate requests; if it’s server-side, it uses the http module to initiate requests.
Method Parameters
In Vue, React scenarios and server-side, client-side environments, our fetch.ts parameters will be slightly different.
Vue Scenarios
In Vue scenarios, we will pass the instances returned by vuex, vue-router as parameters. Developers can use them at any time. In server-side environments, we will additionally pass the current request context ctx. Developers can get the mounted Custom Service or ctx.request and other object information through ctx. This depends on the specific parameter implementation when server-side code calls the core module.
// vue3 fetch.ts
import { Params } from '~/typings/data'
export default async ({ store, router, ctx }: Params) => {
const data = __isBrowser__ ? await (await window.fetch('/api/index')).json() : await ctx?.apiService?.index()
await store.dispatch('indexStore/initialData', { payload: data })
}
// typings/data.d.ts
import type { ParamsNest } from 'ssr-plugin-vue3'
import { IndexData } from './page-index'
import { Ddata } from './detail-index'
interface IApiService {
index: () => Promise<IndexData>
}
interface ApiDeatilservice {
index: (id: string) => Promise<Ddata>
}
export type Params = ParamsNest<any, {
apiService: IApiService
apiDeatilservice: ApiDeatilservice
}>
React 场景
在 React 场景,我们在 服务端 会将当前请求的上下文 ctx 作为参数传入。开发者可以通过 ctx 拿到上面挂载的 自定义 Service 或者 ctx.request 等对象信息。这取决于服务端代码调用 core 模块时的具体入参实现。在前端路由切换时,也就是客户端 fetch 数据场景。我们会将 react-router 提供的路由元信息作为参数传入。
// react fetch.ts
import { ReactMidwayKoaFetch } from 'ssr-types'
import { Ddata } from '~/typings/data'
const fetch: ReactMidwayKoaFetch<{
apiDeatilservice: {
index: (id: string) => Promise<Ddata>
}
}, {id: string}> = async ({ ctx, routerProps }) => {
// 阅读文档获得更多信息 http://doc.ssr-fc.com/docs/features$fetch#%E5%88%A4%E6%96%AD%E5%BD%93%E5%89%8D%E7%8E%AF%E5%A2%83
const data = __isBrowser__ ? await (await window.fetch(`/api/detail/${routerProps!.match.params.id}`)).json() : await ctx!.apiDeatilservice.index(ctx!.params.id)
return {
// 建议根据模块给数据加上 namespace防止数据覆盖
detailData: data
}
}
注意
上述图片指的是用 前端路由 进行跳转的情况。此时的跳转并不会真正的向服务端发起请求。所以数据的获取是在客户端完成的。
如果开发者使用 a 标签进行跳转。则此时可视为完全打开一个新页面。此时的数据获取操作仍然是在服务端完成
不同场景实现差异
在 React 场景以及 Vue 场景我们的切换路由 fetch 数据的时机略有不同。之所以会有差异这里是为了选择不同框架实现起来最简单好用的方式。
在 React 场景,我们会用一个 高阶组件 包裹在所有的页面级别组件外部。在 useEffect 中获取数据。所以我们的行为会是跳转后立即打开跳转后的页面组件,当执行完 useEffect 的逻辑后拿到数据修改 Context 再触发组件的重新 render
在 Vue 场景,我们会在 beforeResolve 钩子调用跳转后的页面组件的 fetch 所以我们会在拿到数据后,才能够打开新页面
补充内容 (todoList)
通过上面的内容开发者可以知道在一个服务端渲染应用中我们应该怎么获取数据了。但是比起纯客户端应用我们还是有一些不足如下
- 只能够获取页面级组件数据,不包含子组件
- 必须通过静态方法来获取
针对第一个问题, 在 Vue 场景非常容易解决。我们可以直接在组件对象中拿到当前依赖的子组件。通过定义一些规范,我们可以支持子组件 fetch 文件的获取执行。我们将会在之后的版本支持这一功能。
在 React 场景略麻烦,react-graphQl-apollo 的解决思路是将组件在服务端渲染两次。第一次渲染时我们可以拿到当前的组件具有哪些子组件并且可以拿到子组件上定义的静态方法。进行收集并调用。在第二次渲染的时候将收集的数据与组件结合变成完整的字符串。当然这样的缺陷就是渲染两次会对性能造成一定影响。但也是一个思路
针对 double rendering 以及 静态方法的问题,我们都可以通过 React Suspense 来解决。Suspense 的概念有些丰富,这里不进行详细描述。这里摘录官网的示例代码进行讲解
// This is not a Promise. It's a special object from our Suspense integration.
const resource = fetchProfileData();
function ProfilePage() {
return (
<Suspense fallback={<h1>Loading profile...</h1>}>
<ProfileDetails />
<Suspense fallback={<h1>Loading posts...</h1>}>
<ProfileTimeline />
</Suspense>
</Suspense>
);
}
function ProfileDetails() {
// Try to read user info, although it might not have loaded yet
const user = resource.user.read();
return <h1>{user.name}</h1>;
}
function ProfileTimeline() {
// Try to read posts, although they might not have loaded yet
const posts = resource.posts.read();
return (
<ul>
{posts.map(post => (
<li key={post.id}>{post.text}</li>
))}
</ul>
);
}
在 resource.posts.read() 中,我们会进行一个异步的获取数据的操作。当然它返回的并不是一个 Promise 对象,而是一个特殊的 Suspense integration。在组件渲染的过程中,会等待 posts 的数据真正返回后,在进行具体的 render 逻辑。也就是我们用同步的写法来描述了一个异步的操作。
当然目前 Suspense 的特性并没有成熟,特别是与服务端渲染结合这一块还有许多问题要解决。但是也是一个未来的发展思路。值得关注。