
简介
v8-profiler-rs 是一个使用 Rust 开发的用于在线智能化的分析 V8 heapsnapshot 堆快照的项目。帮助使用到 V8 引擎的应用开发者,例如 Node.js/Chrome/Deno/Electron 等程序,旨在帮助开发者更直观的理解程序内存结构以及辅助定位内存泄漏问题。
在线地址
我们部署了一个在线网站可以实时上传 V8 内存快照结果并分析。建议使用 Safari, firefox 浏览器访问,实测在这些浏览器下 wasm 执行性能显著优于 Chrome。
更新记录
-
2023.6.12 以
percentangle为维度进行排列。即shallow size / retained_size的比例,如果一个节点被GC后释放的内存远超自身的内存极有可能存在问题 -
2023.4.9 支持在
Firefox浏览器下使用Wasm + WebWorker模式解析 -
2023.3.30 实现
Wasm + WebWorker多线程模式解析,但此方案在Apple M1/M2的CPU架构下无法工作 -
2023.3.29 实现
Wasm + WebWorker模式解析,避免解析过程中网站无响应,WebWorker多线程解析模式开发中 -
2023.3.27 实现 Rust 多线程解析快照文件,支持以二进制文件形式调用
已实现的功能
🚀 表示已经实现的功能,本应用在持续更新中,更新内容将会及时同步到 README.md 当中,敬请关注。如果本应用对你有帮助,麻烦点个 Star ✨
| 里程碑 | 状态 |
|---|---|
| 解析V8快照生成完善的节点信息 | 🚀 |
| 查看节点所在源码位置, 查看节点所属构造函数 | 🚀 |
| 生成分析报告能力 | 🚀 |
| 提供 Webassembly 和 Rust Http 两种调用方式 | 🚀 |
| 支持前端可视化能力 | 🚀 |
| 支持根据节点 id 和节点名称筛节点选 | 🚀 |
| 支持筛选节点数量 支持查看具体节点的详细引用关系 | 🚀 |
| 支持筛选节点的引用深度和过滤引用个数 | 🚀 |
| 支持对比两个快照文件 | 🚀 |
| 支持两种对比类型筛选新增节点/筛选GC大小增大节点 | 🚀 |
| 支持自动化根据节点数量过滤非业务节点信息 | 🚀 |
| 支持上传分析本地序列化后的 JSON 文件 | 🚀 |
支持 Rust 多线程解析快照 |
🚀 |
实现 Wasm + WebWorker 模式解析,避免解析过程中网站无响应 |
🚀 |
实现 Wasm + WebWorker多线程 模式解析 |
🚀 |
为什么用 Rust
解析 V8 内存快照的过程中涉及到大量的计算操作。而 CPU 密集型场景天生是 js 所不擅长的。
在阅读完 Chrome 官方分析内存工具的完整源码后,发现其中为了保证性能使用了大量的奇技淫巧,代码复杂度很高且不利于二次开发。
而 Rust 非常适合这种场景能够在保证代码可读性的同时拥有优秀的性能。同时 Rust 在多线程并发场景优秀的能力是我们所需要的,这个解析计算逻辑用多线程来优化是再也适合不过的了。我们在后续版本中将会不断的优化计算性能。
本应用的解决思路可应用到任何带 GC 的编程语言当中,我们在之后将会尽量支持更多编程语言的内存分析。
最后 Rust 官方对 Webassembly 的支持非常优秀,我们可以轻易的将 Rust 代码编译为 Webassembly 在浏览器中调用。
解析超时问题解决方案
在超大文件的情况下可能会出现 Wasm 内存溢出解析时间过长等问题。出现此问题的话可选择使用 Safari, Firefox 浏览器解析。或使用我们之后将会实现的 多线程 解析方案或采用下列方案来临时解决。
直接上传本地序列化后的文件
下载不同平台的 Rust 编译后二进制文件后直接本地调用
请根据当前的平台架构选择对应的二进制文件下载执行,下载地址
由于浏览器场景下对超大文件的解析有可能会出现浏览器假死的现象。如果开发者想获得最棒最稳定的解析速度,我们提供了 Rust 编译的 Package 可以直接在本地解析生成序列化后的节点信息 JSON 文件,同样可直接上传到网站分析,跳过网站解析的步骤。
$ ./v8-parse --help # shop cli argument
$ ./v8-parse -i ./big.heapsnapshot -o ./result.json # 输入文件big.heapsnapshot 输出 result.json
$ ./v8-parse -i ./big.heapsnapshot -o ./result.json -p # 多线程模式解析提示解析速度
可将解析后的 result.json 文件直接上传分析。

答疑群
本应用目前在不断更新中,如果你遇到问题或者有新的想法,欢迎提issue
注: 我们优先鼓励通过 issue 来交流问题,将会以最快的速度回复,如果你有其他特殊的需求也可以添加下方私人微信加入交流群一起讨论,加好友请备注v8-rs交流!私人微信拉群后会自行删除好友敬请谅解
赞赏
如果你觉得本项目对你有帮助,欢迎请作者喝杯咖啡,你的支持是我最大的动力!
前置知识
在使用本工具之前,我们将会向你介绍下面的一些前置基础知识。如果你发现本手册所写的内容有偏差请及时提 Issue 纠正
GC 算法
主流的垃圾回收算法分为 引用计数 和 标记清除 两种。由于 引用计数 算法会存在循环引用的问题。所以目前主流的具备 GC 的语言几乎都是采用 标记清除 算法来进行垃圾回收。
即每次执行 GC 时从 GC Roots 根节点(注意这里说的根节点不是浏览器环境的 window 或是 node 环境的 global)所不能访问的节点将会被回收掉。
内存节点一般是以有向有环图的结构在内存中存在的。
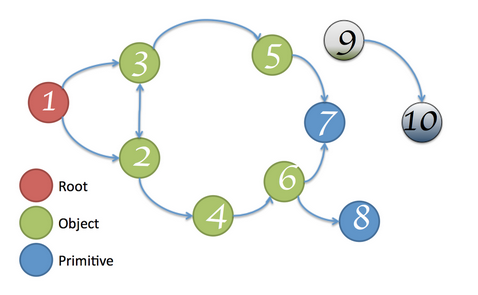
如上图所示,9,10节点无法从 Root 1 节点访问,所以 9,10节点将会被回收。
支配树
上面的图是我们可以直接从内存快照中得到的直接内存关系图,我们将其称之为生成图。在进行实际 GC 分析的时候我们一般会使用支配树算法,来进行生成图转换为支配树结构来更好的进行分析。
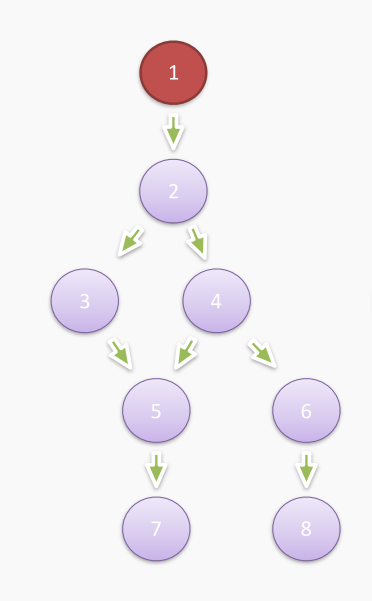
如上图所示,我们可以发现,从根节点1到达节点5有两条道路,也就是说无论是删除节点3还是节点4,我们仍然可以从节点1访问到节点5,此时节点5并不能被回收。只有删除节点2才能够回收节点5,所以我们将节点2称之为节点5的直接支配节点。
明白了上面的含义,我们就可以通过支配树算法生成支配树。
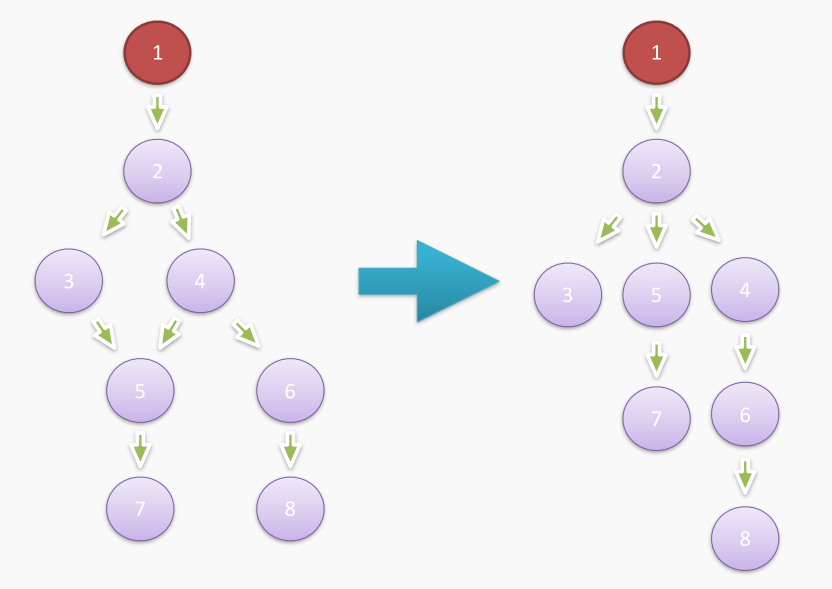
支配树对我们计算节点的 retained_size 属性非常有帮助。即一个节点被 GC 后总共能释放的内存大小。了解更多的详细信息可以查看Chrome文档手册
使用手册
具备上面的基础知识之后,接下来该介绍本工具具体做了什么以及应该怎么使用了。
定义节点结构
首先我们定义一个 V8 内存节点的数据结构如下
pub enum JsValueType {
// 在 Rust 中表示 JS 类型,可能有 String 和 Number 两种类型
JsString(String),
JsNumber(usize),
}
pub struct Node {
pub node_type: JsValueType, // 节点类型
pub name: JsValueType, // 节点名称
pub id: JsValueType, // 节点 id
pub self_size: JsValueType, // 节点自身大小
pub edge_count: JsValueType, // 节点的子节点数量
pub retained_size: Option<usize>, // 节点被 GC 后可完全释放的大小
pub edges: Vec<Edge>, // 节点的子节点
pub parents: Vec<usize>, // 节点的父节点
pub constructor: String, // 构造函数名称
pub source: Option<String> // 所在源码位置
}
在上面的结构体中,除了 retained_size/source/constructor 之外其余的信息我们都可以直接通过 V8 HeapSnapShot 计算得到。
而retained_size 是我们最需要关注的属性,通过上面的内存图结构可以看到。一个节点被删除后,其所支配的节点也将一并被删除。也就是此时可回收的内存大小为所有被释放的节点大小总和。
通过上述介绍我们可以发现,容易产生内存泄漏的节点往往具有比较大的 retained_size , 或是 self_size 与 retained_size 差距很大的节点。
注意:这里还有一个非常重要的信息是, Node 与 Edge 的关系存在 weak retainer 的关系,也就是弱引用,在进行 GC 时,不会将弱引用关系计算在内。类似于 JS 中的 WeakMap 数据结构。在图表中我们将会用不同的线条来表示强弱引用关系。
代码实战
以下列经典的内存泄漏代码为例子,leak 引用了函数外层的 theThing, 而 someMethod 又因为闭包的机制引用了 leak, 每次有新的请求产生将会创建新的 theThing 对象,如此产生了无法回收的引用链条导致内存泄漏。
下面来讲述如何运用本工具来发现内存泄漏。
const express = require('express');
const app = express();
const fs = require('fs')
//以下是产生泄漏的代码
let theThing = null;
let replaceThing = function () {
let leak = theThing;
let unused = function () {
if (leak)
console.log("hi")
};
// 不断修改theThing的引用
theThing = {
bigNumber: 1,
bigArr: [],
longStr: new Array(1000000),
someMethod: function () {
console.log('a');
}
};
};
let index = 0
app.get('/leak', function closureLeak(req, res, next) {
replaceThing();
index++
if (index === 1) {
// 生成初始态快照
const stream = require('v8').getHeapSnapshot()
stream.pipe(fs.createWriteStream('small-closure.heapsnapshot'))
}
if (index === 40) {
// 生成中间态快照
const stream = require('v8').getHeapSnapshot()
stream.pipe(fs.createWriteStream('medium-closure.heapsnapshot'))
}
if (index === 50) {
// 生成最终态快照
const stream = require('v8').getHeapSnapshot()
stream.pipe(fs.createWriteStream('big-closure.heapsnapshot'))
}
res.send('Hello');
});
app.listen(3001);
生成 heapsnapshot 文件
如何生成 heapsnapshot 文件,在 Node.js >= 11.13.0 中我们可以直接通过内置的 V8 模块来生成。在老版本的 Node.js 中我们也可以通过 heapdump或 v8-profiler-next 来生成。本质都是调用了 Node.js 的 V8 C++ 代码 来生成内存快照。我们在之后也会提供 Rust binding 来访问 V8 API 来实现更多丰富的能力。
isolate->GetHeapProfiler()->TakeHeapSnapshot(Nan:: EmptyString());
上传文件分析
在 在线工具 中,我们可以通过选择本地文件进行上传。或者如果你想体验本工具的能力。我们已经默认内置了上述代码生成的内存快照进行分析。
点击左侧查看默认示例,我们将会通过上述代码的内存快照来生成图示。目前的计算时间根据内存快照的大小,原生的 Rust 代码大概需要运行 0-6s 经过 Webassembly的损耗后大概需要 3-20s 左右的时间,目前的算法还有一些可以优化的空间,我们将会在之后的版本中不断的优化性能。
在控制面板中我们提供了诸多控制图表绘制参数的控制能力,通过这些功能我们可以轻松的过滤无关信息来获取想要的信息同时可以获得流畅的绘制性能。
排列节点
通过上面的代码,我们生成了三个快照文件。首先上传 big-closure.heapsnapshot 进行分析。
在上面我们提到了,容易发生内存泄露的节点往往是那些 Retained Size 很大的节点。所以我们默认按照 Retained Size 通过箭头的顺序 从大到小 排列。选取前 50(数量可修改)个节点进行展示。
这里我们以不同的颜色代表不同类型的节点。分别是黑色的系统原生节点,紫色的 JS 层节点以及蓝色的普通节点。开发者一般只需要重点关注紫色节点即可。
我们之后将会进行更加细致的分类展示。
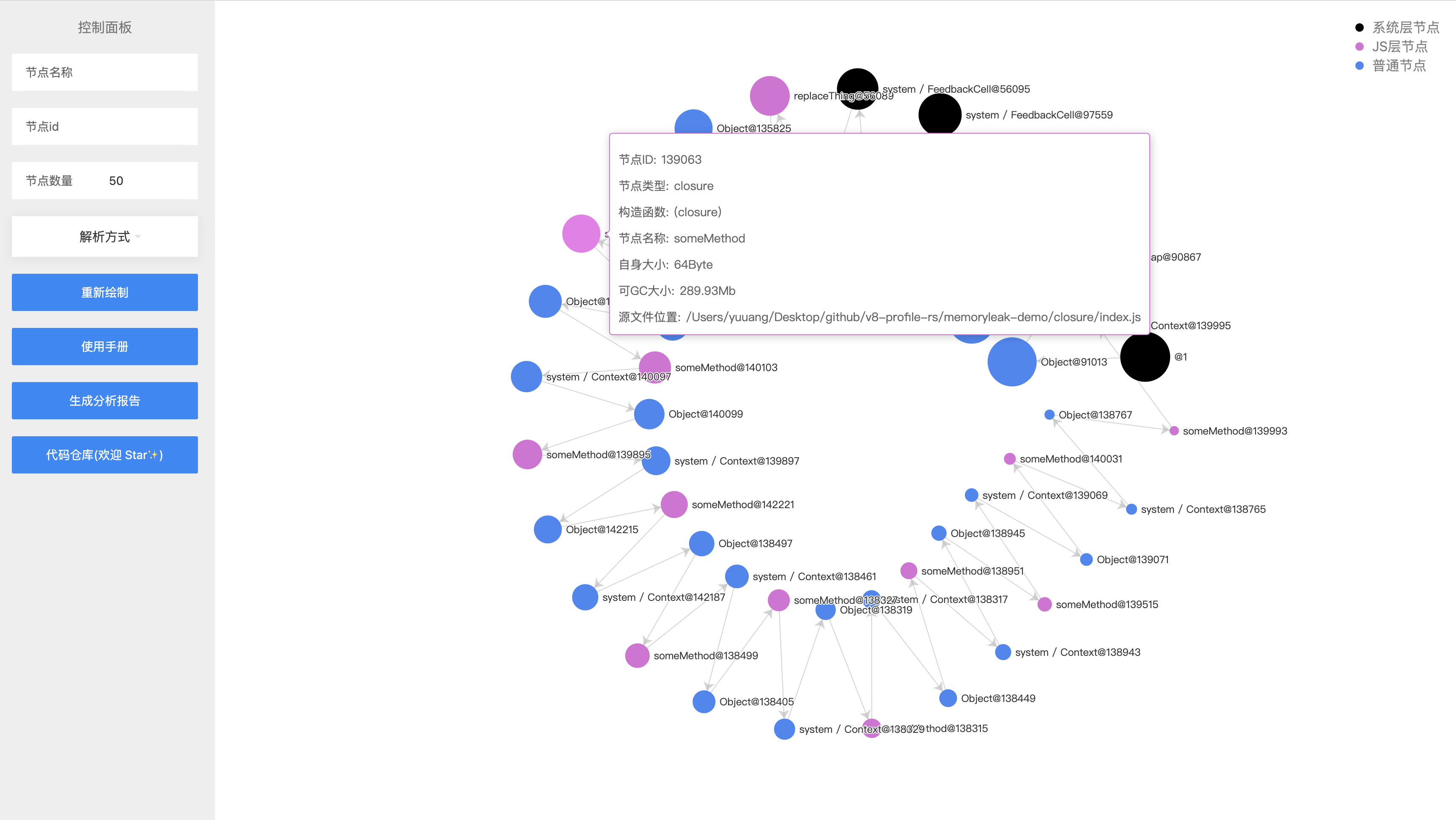
当鼠标 hover 到节点时,我们将会展示节点的详细信息包括 节点id、节点名称、节点大小、节点可被回收大小、节点源码位置(如有) 、节点构造函数名称
节点面积越大,代表可被回收的大小越大
通过图表我们可以看到在业务节点中最大的节点名是 replceThing,someMethod 的节点,并且someMethod节点存在了很多个。这时候我们点击节点,将会展示其的具体引用关系。
查看节点引用关系
点击最大的 someMethod 节点,我们将会展开其信息, 并将该节点以红色展示。红色边代表强引用,黑色边代表弱引用,引用关系以箭头表示。
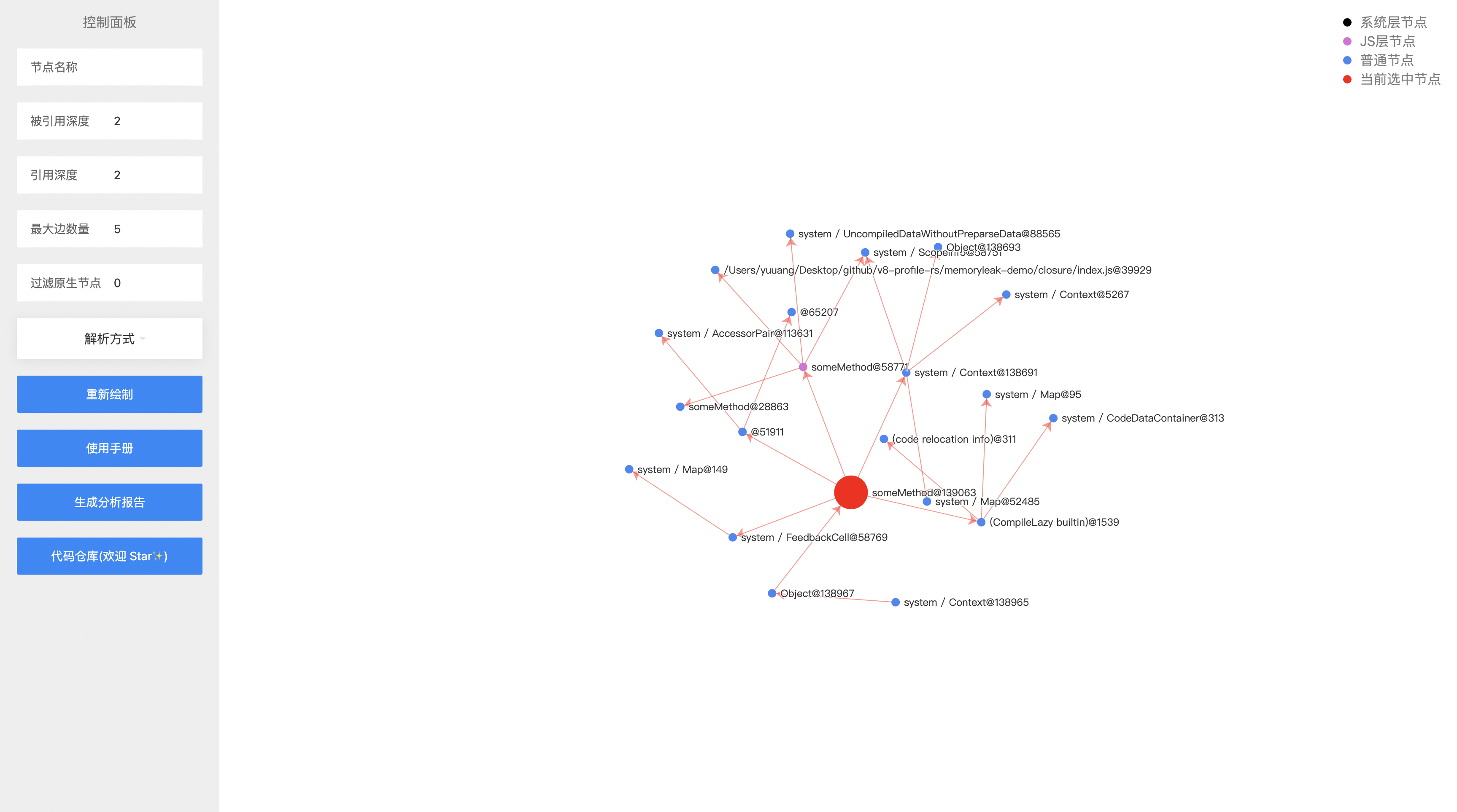
这时候出现了该节点的引用节点和被引用节点。此时存在较多的无关干扰信息,由于该节点是最大的节点,我们只需要关注它引用了哪些节点即可。此时通过左侧的控制面板,设置 被引用深度 为0,引用深度 为 3,边数量调整为 3,这是针对不同的内存快照可能需要不同的调整参数。开发者可以自行多尝试几次
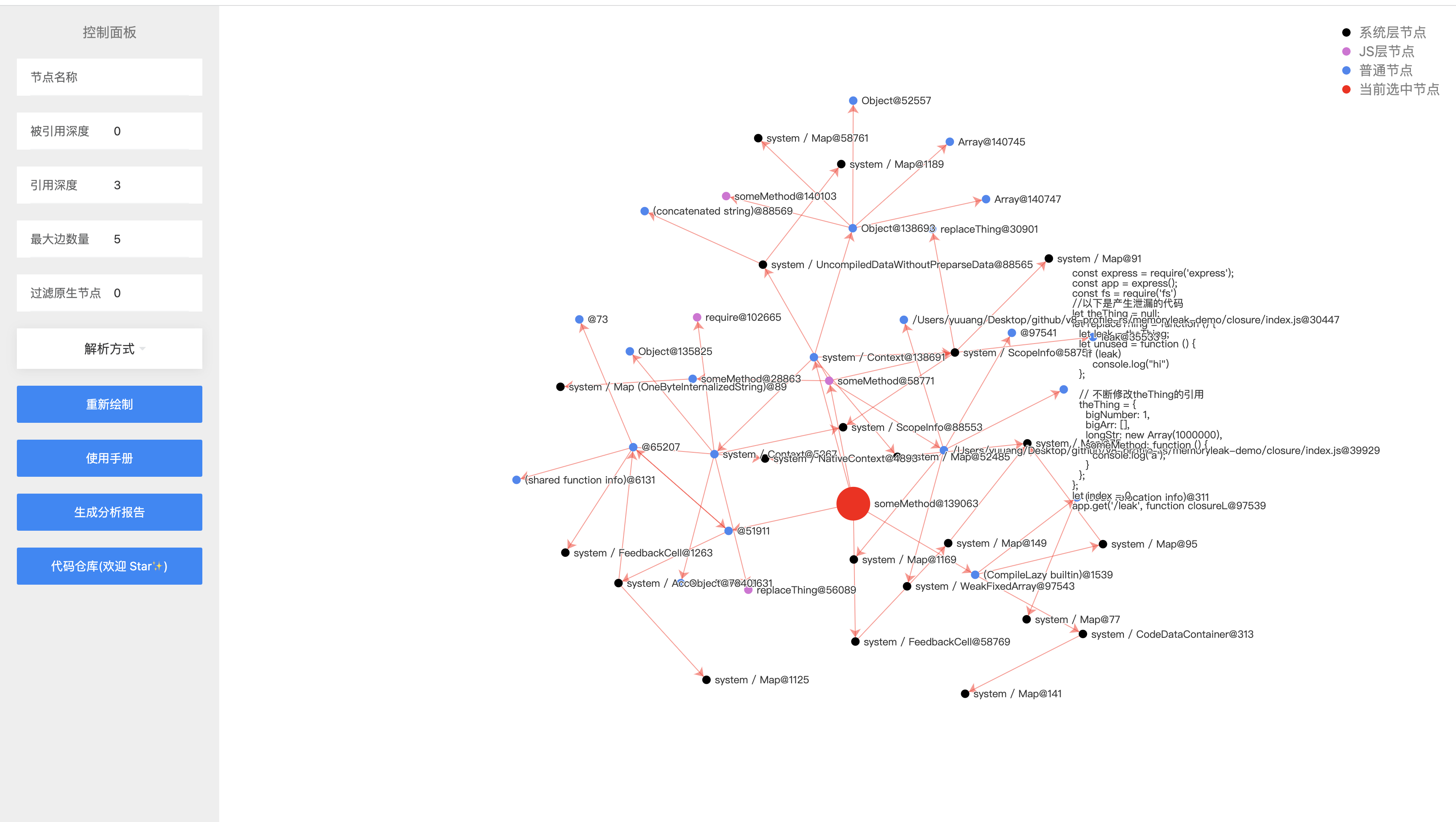
如果我们觉得信息太繁杂,这时候设置过滤原生节点值为 1,我们将会过滤黑色的节点引用关系
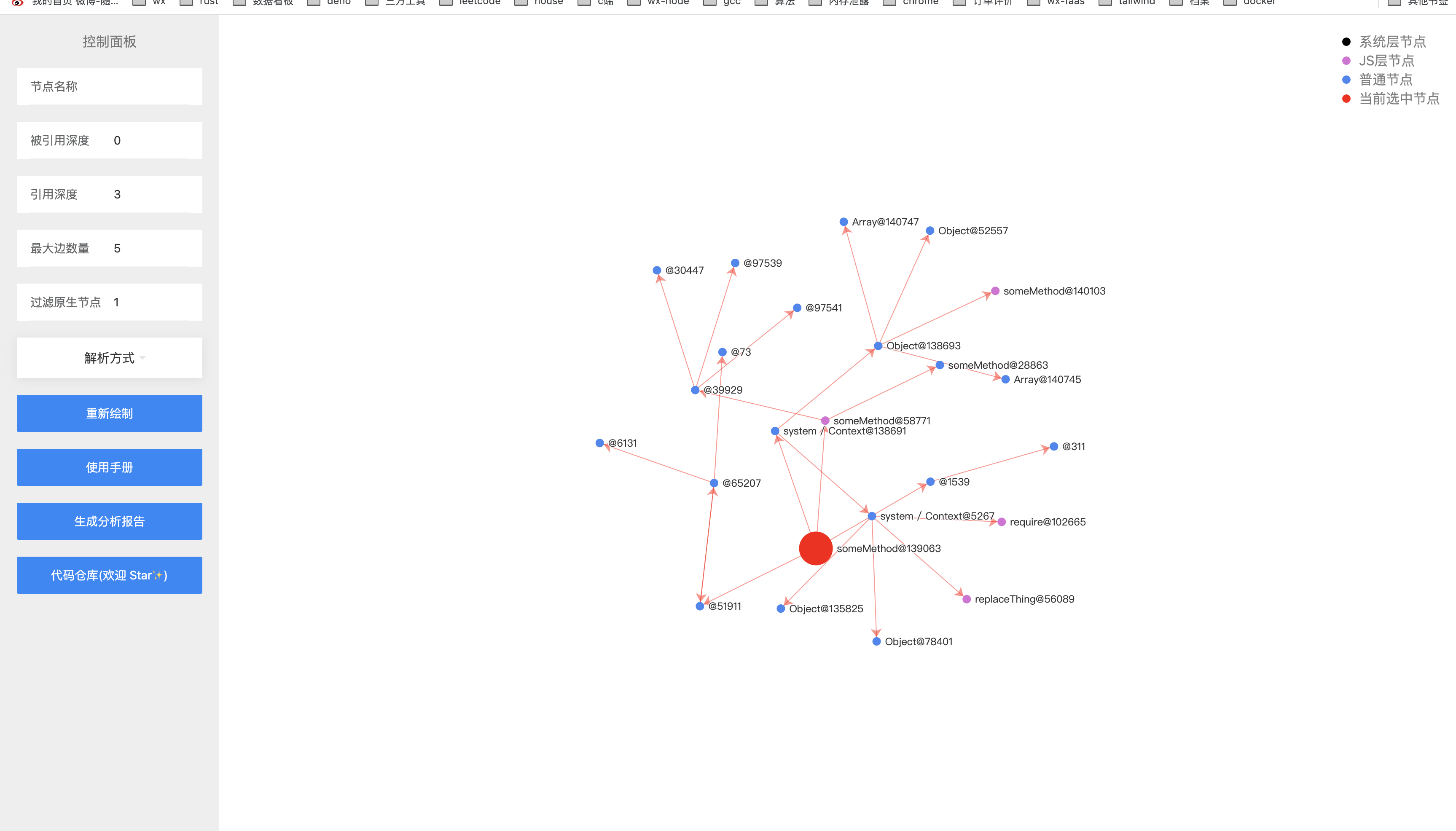
这样瞬间就清爽了很多。在这一步基本可以定位内存泄漏原因在 someMethod 这个节点了,这时候在通过节点名称进行过滤,来查看完整的引用关系链

查看分析报告能力
如果你仍然觉得上面的步骤太繁琐,我们提供了生成分析报告能力。帮助开发者智能分析可能会出现问题的地方。
点击面板的分析报告按钮。我们目前将会从以下两个维度进行分析。
- JS 层重复节点

- JS 层可释放内存过大节点

快照对比
通过快照对比我们可以迅速找到在两次快照中被创建的新节点,以及相同节点但是可GC大小增大的节点。这些节点往往代表着内存泄漏。
同时上传 medium-closure.heapsnahshot 和 big-closure.heapsnahshot
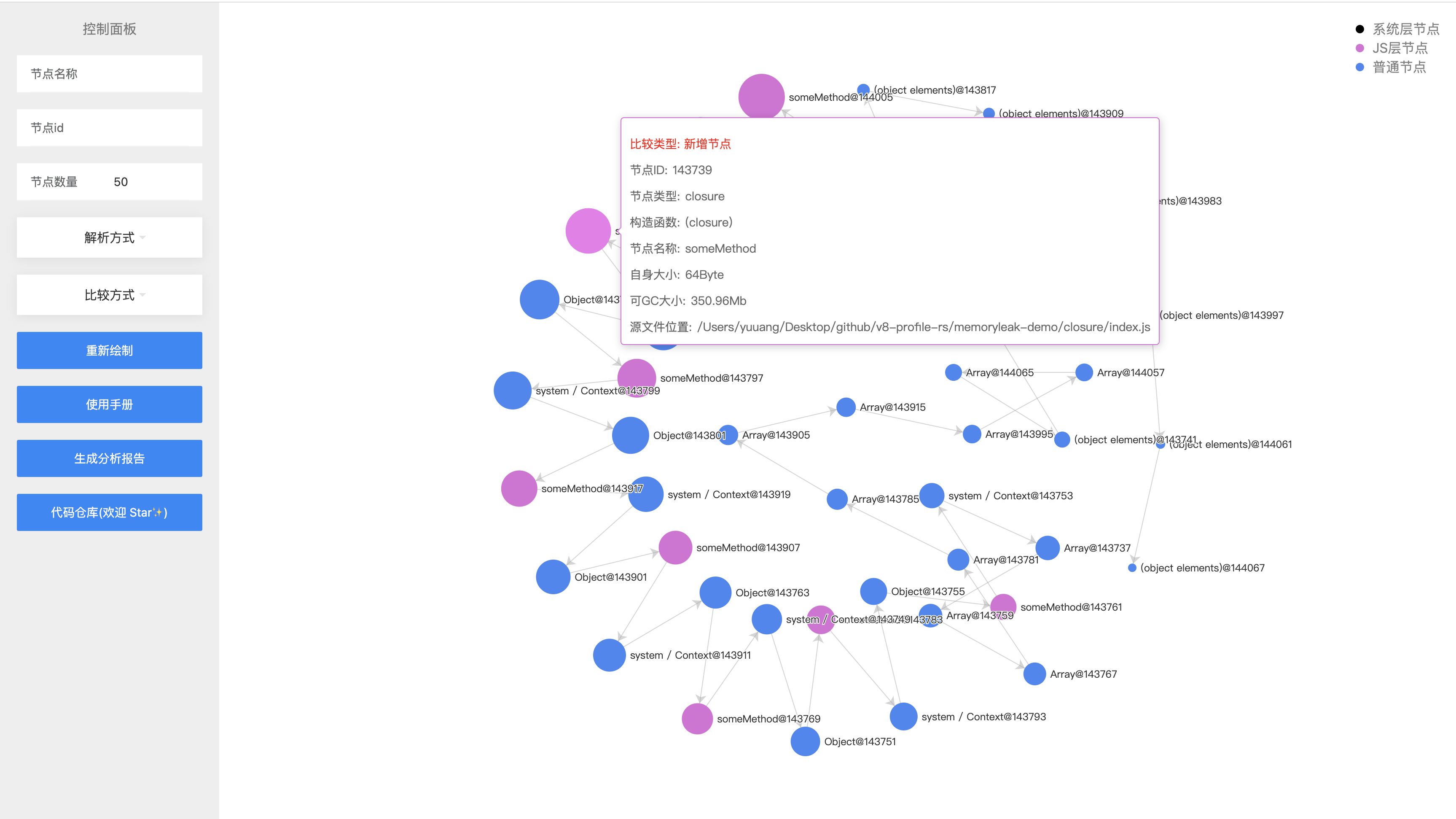
默认的对比方式是新增节点。同样我们将会按照 retained_size 的大小,从大到小排列新增节点。可以看到新增的节点中与业务相关的节点,多了很多 someMethod 节点。
为了更好的看到占用内存增大的节点,这时候我们上传 medium-closure.heapsnahshot 和 big-closure.heapsnahshot
将对比类型改为 增长节点 并点击重新绘制
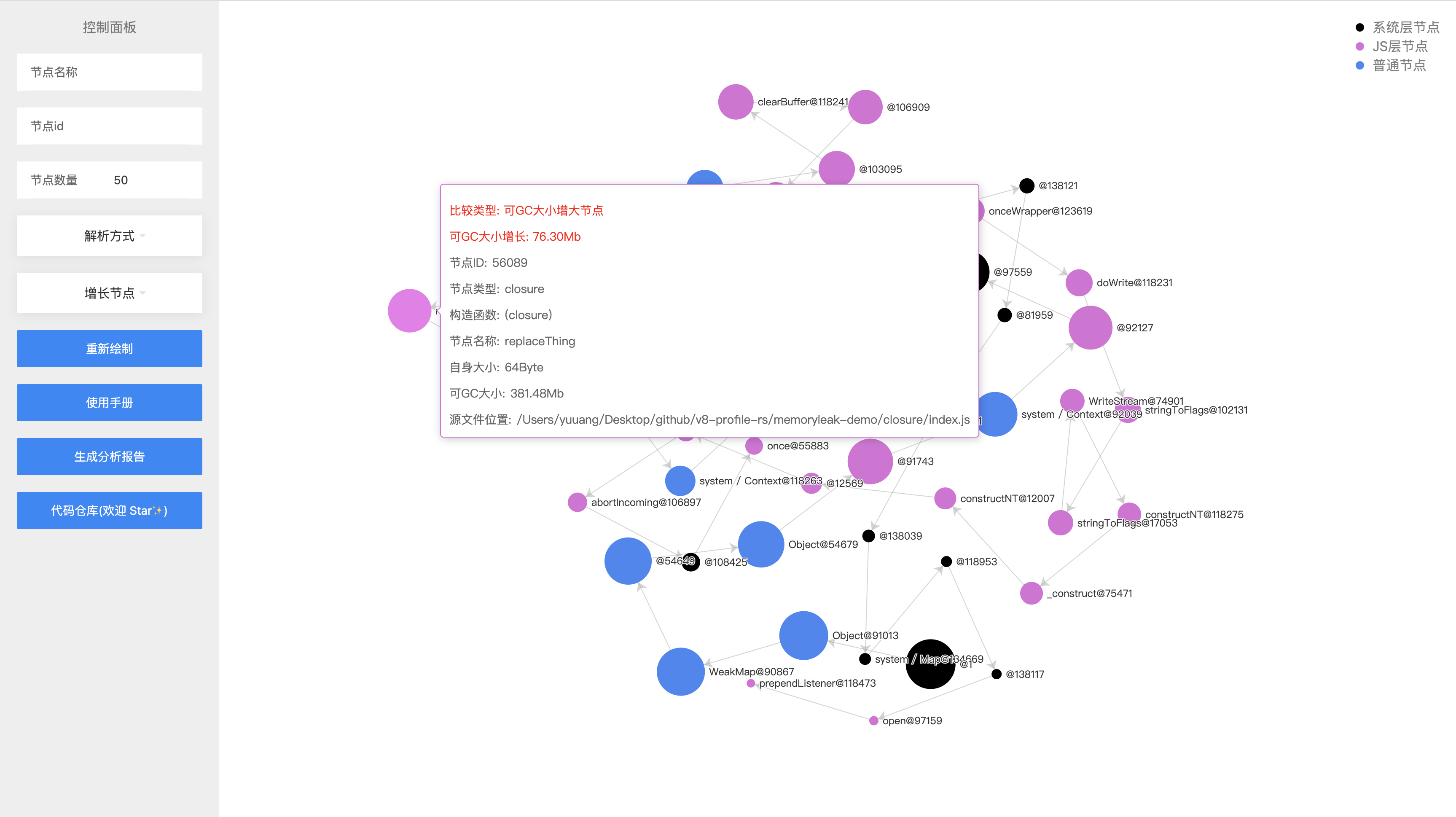
此时,我们将会比较相同的节点,在两次快照中,可被 GC 回收大小的增长。并按照大小排列。
可以看到 replaceThing 这个业务代码中的节点,在请求次数从 40 次到 50次的时候可GC大小增长了 76MB,存在内存泄漏的可能。
多快照分析报告
同样多快照的情况我们也提供了生成分析报告的能力。这里我们会以以下维度进行分析
- 新增节点中重复/占用内存大的JS层节点

如果这些节点 仅存在同一文件 中,则 疑似存在内存泄漏
- 增大节点的增长幅度
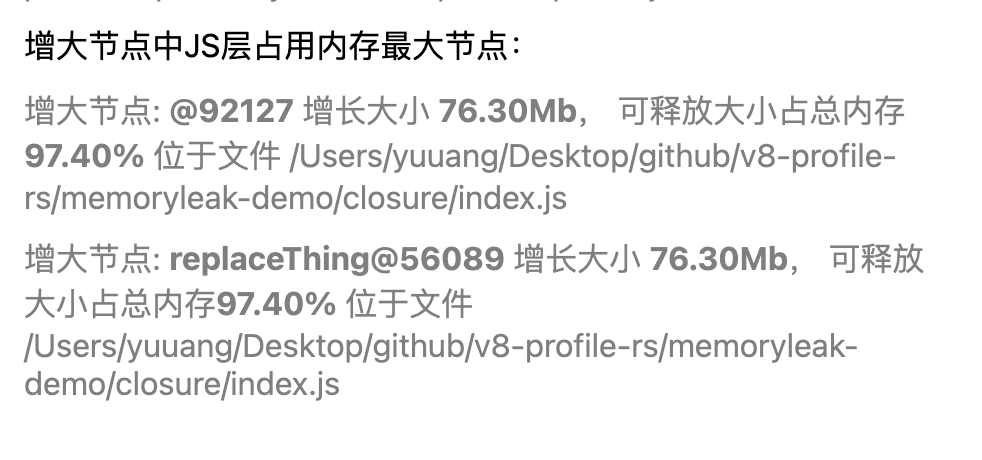
至此,我们的一次分析内存泄漏的过程就完成了。可以看到简单的内存泄漏,我们只需要上传一次快照文件就可以基本定位泄露位置。复杂的内存泄漏情况我们可以通过上传前后两次快照的对比来找到变动的节点。
我们将会在之后持续优化性能以及增加新的分析能力,敬请期待。欢迎 Star ✨